
.webp "send-email")

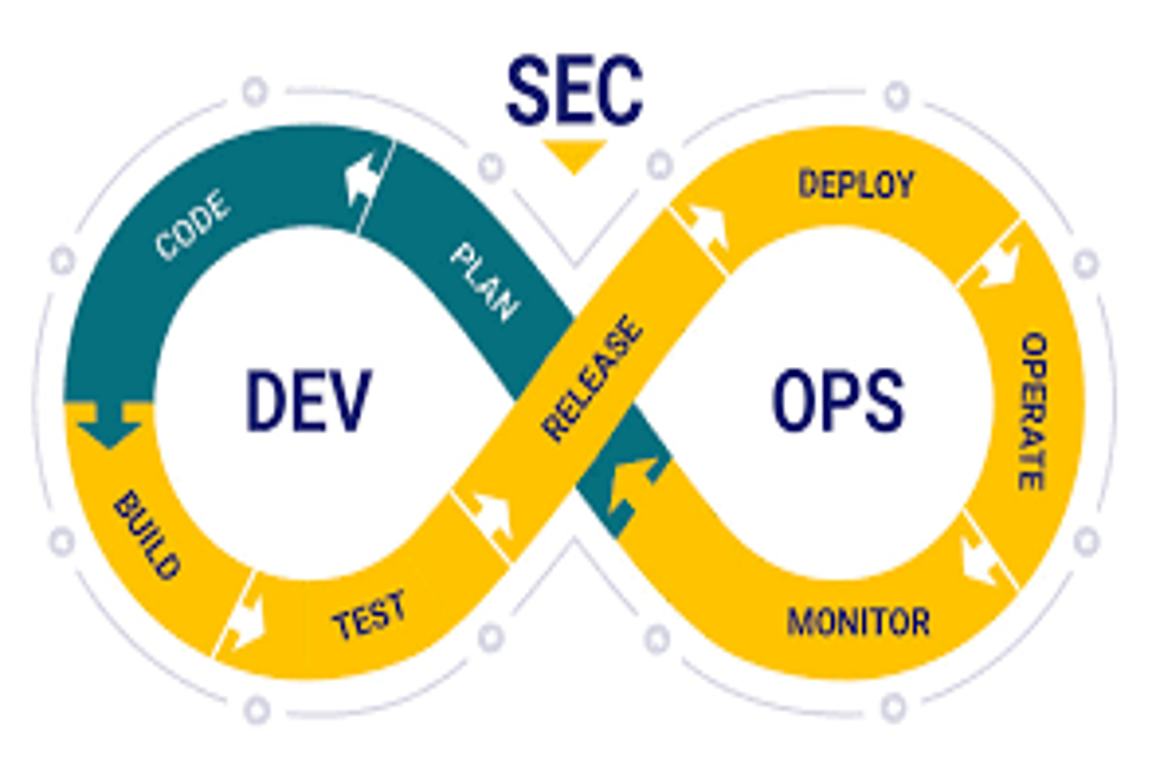
DevSecOps: Integrating Security into DevOps
Author: Charu RajputDate: 6 March 2026 Introduction Modern software development moves very fast with DevOps practices such as Continuous Integration (CI) and Continuous Deployment (CD). While speed improves productivity, it can also introduce security risks if security checks are ignored. This is where DevSecOps comes in. DevSecOps means integrating security into every stage of the […]



